Journey Inside an LLM: A Visual Expedition Through AI's Neural Pathways
Visualizing and understanding LLMs in an incredible way.
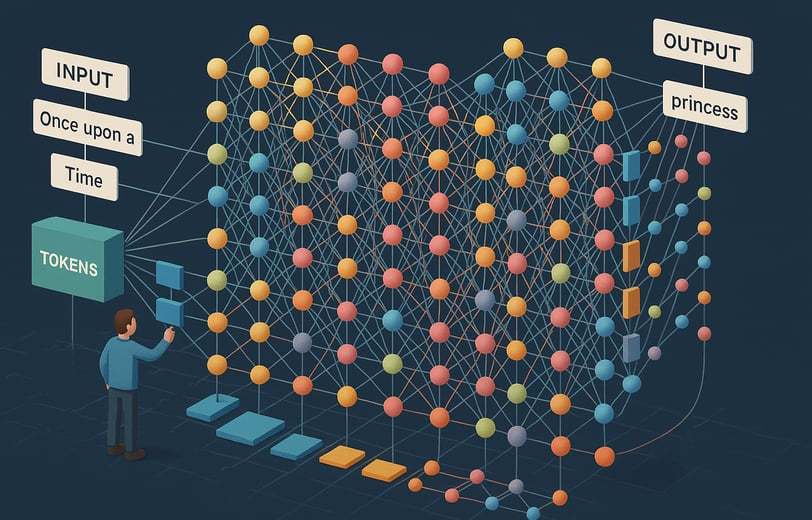
Brendan Bycroft's interactive 3D visualization of LLMs (https://bbycroft.net/llm) offers an extraordinary window into the inner workings of the technology powering tools like ChatGPT. This remarkable digital dissection takes us on a guided tour through the neural pathways of artificial intelligence. Let's embark on this journey together, unpacking each part of this fascinating visualization in everyday language.
The Grand Overview: What Are We Looking At?
Imagine trying to explain how your car engine works by just pointing at the hood. Not very helpful, right? That's the beauty of Bycroft's visualization—it pops the hood on LLMs and gives us a 3D tour of all the moving parts.
What we're seeing is a GPT-style neural network in action, specifically designed to perform a seemingly simple task—sorting letters alphabetically. But don't let the simplicity fool you. This small example brilliantly demonstrates the same architecture that powers the most advanced AI systems today.
Think of it as watching a Formula 1 driver parallel park. The skill set is the same as what's needed on the racetrack, just applied to a more accessible demonstration.
Tokenization: Turning Words Into Numbers (Because Computers Can't Read)
Our journey begins with tokenization—the process where text gets chopped up into bite-sized pieces that the model can digest.
In the visualization, you'll see how input text (like our letters to be sorted) gets transformed into numbers. It's like watching a translator convert English to Computer-ese. "A," "B," and "C" become numerical tokens that the model can process.
Remember when you had to use T9 to text on your Nokia phone? Pressing 2 once for "A," twice for "B," and so on? LLMs do something conceptually similar, except with a vocabulary of tens of thousands of "buttons" and much more sophisticated encoding.
Embeddings: Giving Tokens Meaning in Multidimensional Space
Once we have our tokens, the model needs to understand them in context. That's where embeddings come in—vectors that represent tokens in a high-dimensional space.
The visualization shows these as colorful arrays of numbers. Each token gets its own unique position in this abstract space, where similar concepts live near each other. It's like a cosmic map of language, where "dog" and "puppy" might be neighboring stars, while "refrigerator" is in a different galaxy altogether.
If this reminds you of those awkward middle school dances where similar cliques clustered together across the gymnasium floor, you're not far off. Embeddings are essentially the model's way of organizing a massive linguistic high school into meaningful social groups.
Attention Mechanism: Teaching AI to Focus
Now we get to the real magic—attention. This is where Bycroft's visualization truly shines, showing these complex mathematical operations as vibrant, flowing connections between tokens.
Attention allows the model to weigh the importance of different parts of the input when generating each part of the output. It's like having a conversation at a noisy party—you focus on the person you're talking to while still maintaining awareness of the overall room.
The visualization shows the computation of queries, keys, and values—the three components that enable the attention mechanism. It's like watching a matchmaking service in action: queries (what I'm looking for) get compared to keys (what's available), resulting in attention scores that determine how much each value contributes to the output.
In our letter-sorting example, the model learns which positions to pay attention to when deciding the alphabetical order. If you've ever watched a card player memorize a deck by creating mental associations between cards, you're seeing a human version of attention at work.
Multi-Head Attention: Why One Brain Is Never Enough
The visualization then shows how attention happens in parallel across multiple "heads". Each head can focus on different aspects of the input, much like how you might consult several friends with different expertise before making a big decision.
One attention head might focus on syntactic relationships, another on semantic meaning, and a third on something else entirely. The model then combines these different perspectives for a richer understanding.
It's like those crime shows where detectives put together a case by combining financial records, witness statements, and forensic evidence. Each piece tells part of the story, but the full picture only emerges when they're all considered together.
Feed-Forward Networks: Individual Thinking Time
After all that social interaction in the attention layers, each token gets some solo processing time through feed-forward neural networks.
The visualization depicts these as transformations applied independently to each position in the sequence. It's like students going off to work on individual assignments after a group discussion—each token processes what it learned from attention and develops its own representation further.
These feed-forward networks are surprisingly powerful, consisting of two linear transformations with a non-linear activation function in between. In human terms, it's like taking in information, chewing on it in a creative way, and coming up with your own evolved understanding.
Layer Normalization and Residual Connections: The Unsung Heroes
The visualization doesn't forget the crucial but often overlooked components of modern LLMs—layer normalization and residual connections.
Layer normalization keeps values in check, preventing them from growing too large or too small. It's like having a financial advisor who ensures you're neither blowing all your money nor being too stingy—keeping your budget in a healthy range.
Residual connections allow information to flow directly from earlier layers to later ones. They're like those friends who remind you of important details you might have forgotten during a complex discussion. "Hey, remember when we were talking about X? Let's not lose sight of that."
Without these components, training deep neural networks would be much harder—like trying to build a 100-story building without structural supports or elevator shafts.
Decoding and Generation: From Numbers Back to Words
As we near the end of our journey, the visualization shows how the model generates output tokens one by one. For each position, the model considers all previous outputs and calculates probabilities for what should come next.
In our letter-sorting example, you can watch as the model works through the sequence, gradually figuring out the correct alphabetical order. It's like watching someone solve a puzzle, piece by piece, with each decision informing the next.
The final probability distribution over the vocabulary—represented as a colorful histogram—shows which tokens the model thinks are most likely to come next. It's like seeing the model's thought process laid bare: "I'm 80% sure 'A' comes first, 15% it might be 'B', and 5% chance it's something else."
The Complete Process: Tying It All Together
Bycroft's visualization brilliantly shows how all these components work together in a cohesive system. The data flows through multiple layers of attention and feed-forward networks, with each layer refining the representations further.
What's most remarkable is seeing how a relatively simple architecture—repeated many times with millions or billions of parameters—can learn to perform complex language tasks. It's like realizing that all of Earth's biodiversity comes from different combinations of just four DNA nucleotides, or that all of English literature comes from rearranging just 26 letters.
When you zoom out and see the entire model operating in concert, you gain a new appreciation for both the elegance of the design and the massive computational resources required. It's a humbling reminder that what feels instantaneous to us as users actually involves billions of mathematical operations happening behind the scenes.
Why This Matters: Beyond the Pretty Visuals
This visualization does more than just look cool—it demystifies one of the most transformative technologies of our time. By making the abstract concrete, Bycroft has created an invaluable educational tool.
Understanding how these models work is increasingly important as AI becomes more integrated into our daily lives. It helps us appreciate both their capabilities and limitations. These aren't magical oracles but pattern-matching systems operating on statistical principles—incredibly sophisticated ones, but bound by the data they've seen and the architecture they employ.
The next time you use ChatGPT or another LLM, you'll have a mental model of what's happening under the hood. That text that appears so effortlessly on your screen is the result of token embeddings flowing through attention mechanisms, being processed by feed-forward networks, and finally being decoded into the words you see.
It's like learning how a magician performs their tricks—the magic doesn't disappear, but your appreciation for the craft deepens.
Final Thoughts
Brendan Bycroft's LLM visualization stands as a testament to the power of visual explanation. By rendering the abstract mathematical concepts behind LLMs in three-dimensional space, it bridges the gap between theoretical understanding and intuitive grasp.
As these models continue to evolve and shape our technological landscape, tools like this will become increasingly valuable—not just for AI researchers and engineers, but for anyone seeking to understand the systems that increasingly mediate our interaction with information.
So take some time to play with the visualization. Follow the data as it flows through the system. Watch how attention distributes focus across tokens. And marvel at how these relatively simple operations, repeated at scale, can produce systems capable of generating human-like text. The future of AI may be complex, but thanks to visualizations like this, it needn't be impenetrable.
And remember, the next time someone asks you how ChatGPT works, you can now say "Well, actually..." with the confidence of someone who's seen the matrix behind the curtain.